Event Driven Python AWS

CloudGuruChallenge - Event Driven Python on AWS
After being asked by many friends about transitioning into a DevOps role with no background; I began doing some digging and stumbled upon the Cloud Resume Challenge. The book opens up with a story about a plumber learning to code while dealing with literal shit, then proceeds to give the curious an open-ended challenge to complete.
Some further digging I stumbled upon A Cloud Guru's Event-Driven Python challenge and decided to jump in as a means to overcome my fear of serverless functions and build some new skills.
Database
For the database, I decided to choose something light weight and affordable. DynamoDB looked to be the best option as I was able to quickly launch a table without having to managing credentials. Keeping the stack light and cost-efficient went hand in hand with a serverless stack. The main drawback to this decision is presented when setting up the dashboard. Unfortunately, there are some extra steps required to leverage AWS Quicksight which was a bit surprising for a native AWS tool.
Data Handling in Python
The data manipulation portion of this was new to me, even with a decent background in Python. For manipulating data, I used the pandas library and leveraged dataframes to
manipulate fields and verify the data was as expected. The awswrangler package was used to load and update any records in the database that have been added. I do believe the
function as a sync and will update any tables if the data is not the same, however I have not tested this for the sake of getting this project done. From a data engineering perspective it would
be wise to verify the nature of the awswrangler put command. Once records are updated, I compare the fields in the dataframe with the number of rows in Dynamo to get the number of rows updated.
Infrastructure As Code (IAC)
The IAC portion of this project was quite interesting, as I had to leverage Terraform extensively to package the lambda application and deliver it to AWS. Since the repository was public (and also since it's good practice) I had to take into consideration publishing variable files to Git, as that would expose some ARN IDs, emails and AWS credentials. This issue becomes more apparent when hooking up the CI component of this project.
A notable problem was dealing with delivering third party packages to lambda. Thankfully awswrangler has a lambda layer that we can pull in
without any additional packages to build.
Notifications
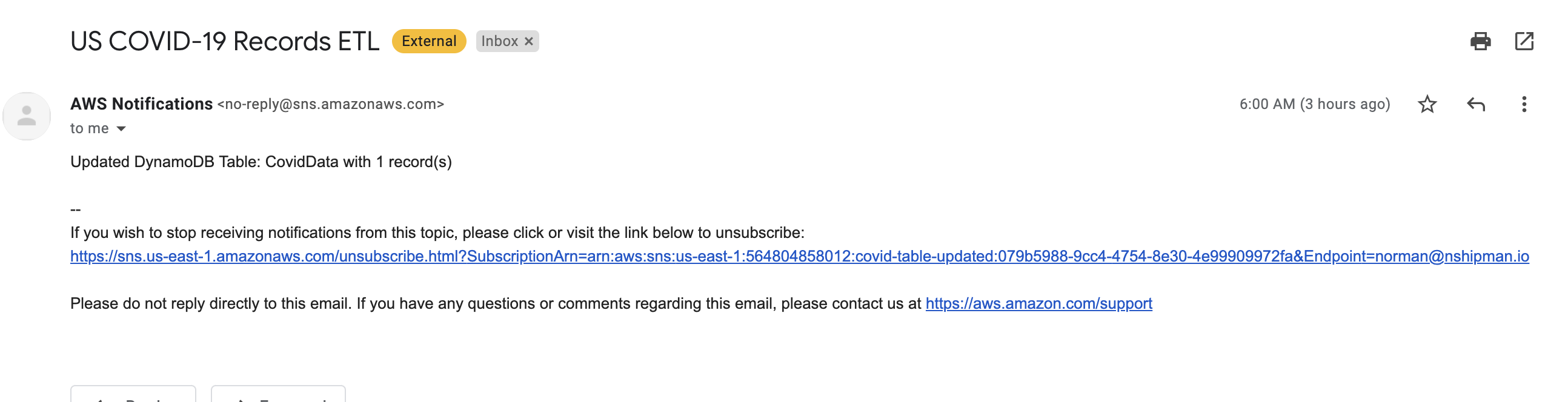
Notifications were easy to hookup, leveraging AWS's SNS subscription. For flexibility and security, I configured the SNS topic via environment variable to the application. Anytime the job would succeed and update records, a message would be emailed letting the user know how many records were added to the table.
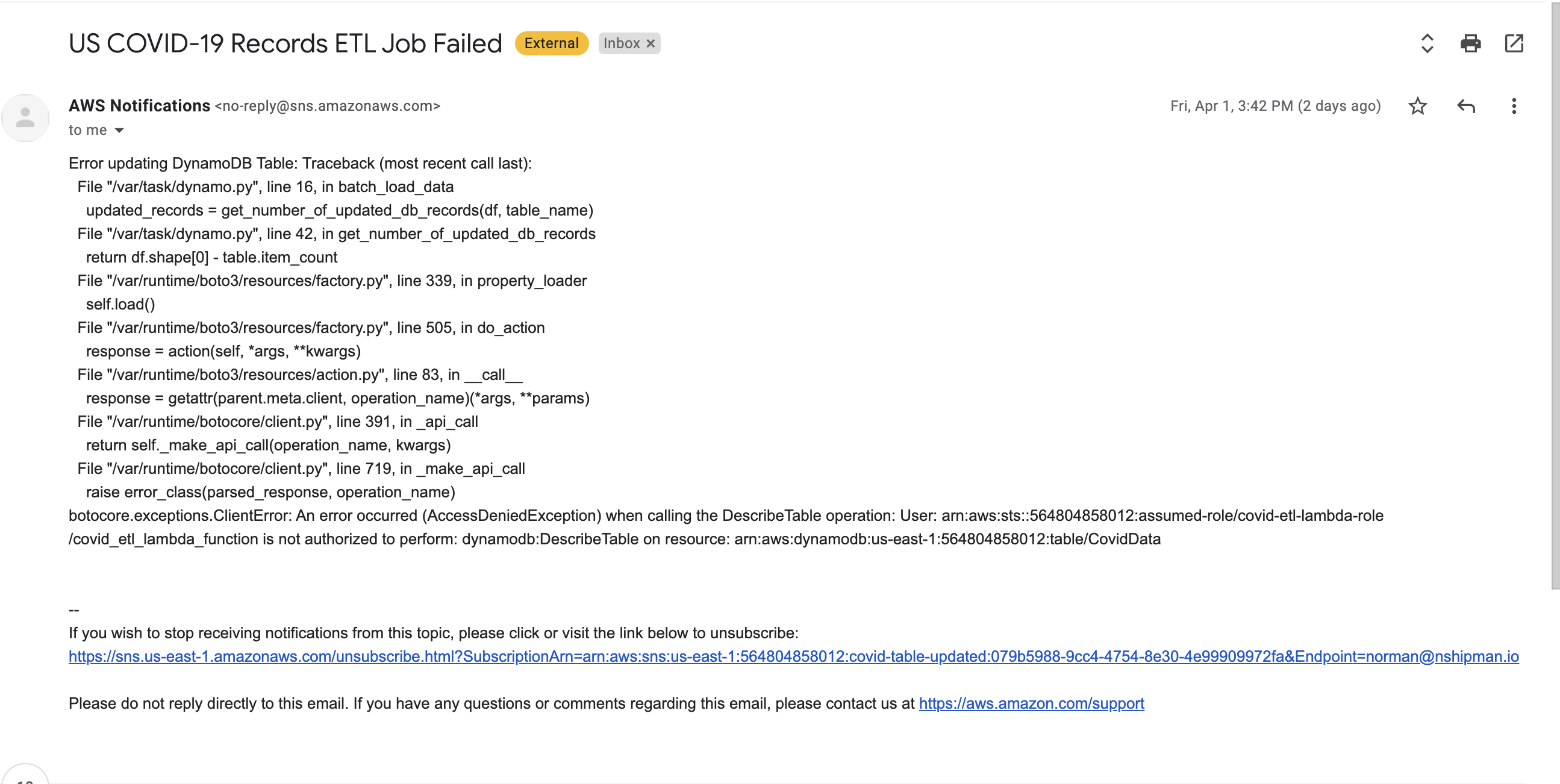
Whenever the job fails, the recipient will receive a notification with the python error message, which has proven very helpful when you need to debug any permission or code issues.
CI/CD
For CI/CD, I leveraged Github actions to deploy the Terraform changes. The workflow involves, opening up a Pull Request to run a terraform plan
job. This way we can ensure our changes won't fail on the plan before merging. We can check out any updates in the comment section of the pull request.
Upon merging to master, the job will run a terraform apply and updated our changes to AWS.
Follow this Terraform tutorial to learn how to leverage github actions to automate terraform deployments.
Wrap Up
This was a great project to explore the challenges a data engineer may face when setting up ETL pipelines. The most challenging parts of this challenge were deploying the lambdas to AWS and setting up a secure CI/CD pipeline. I can happily say, this entire project has a monthly cost of ~$10 even with active testing. You can find the source code for the project on GitHub.